aez-notes
Table of Contents
![]()
Learning
Further reading
Blog posts
- An opinionated guide to Haskell in 2018
- Can you make heterogeneous lists in Haskell? Sure — as long your intent is clear and on the waybackmachine.
- Two interesting posts on type safety by Matt Parsons
- Foo to Bar: Naming Conventions in Haskell
- Numbers of Every Shape and Size
- The trick to avoid deeply-nested error-handling code
- Haskell mini-patterns handbook
- common stanzas to keep cabal files DRY
- Discussion of totality of functions
- Structure your Errors
Unread blog posts
- unread Fix(ity) me
- unread Introduction to
singletons1 (dependent types) - unread Existential quantification
- unread basic syntax extensions from the School of Haskell (reference material)
Documentation
Books
- Learn You a Haskell for Great Good!
- Haskell (Almost) Standard Libraries I haven't read any of this but it sounds good.
Tooling
Debugging
- Load the relevant module:
λ> :load <module.hs> - Set a break point:
λ> :break <identifier>where identifier can be a function name or line number - Evaluate relevant expression and inspect it with
:λ> :print <identifier>
In the output _result is the name of the value of the current expression. When
working with let expressions the break point will be upon the body of the
expression rather than any of the values bound. The break command can also be
used to set breakpoints in other modules with :break <module> <n>, although
you have to be a little bit careful in this situation, since some functions may
go out of scope as you move between modules.
You can always use :help to get a listing, but here are some useful functions
| Command | Function |
|---|---|
:list |
See current line |
:print |
Print variable |
:step |
Step to next expression |
:continue |
Run to next break |
:show breaks |
Show break points |
:delete <n> |
Delete break n |
Note that because the expressions are only lazily evaluated you may need to use
the seq function to force their evaluation in order to see what they are. You
can fmap (flip seq ()) onto a functor to force the evaulation of its contents.
Less recommended way of debugging
The trace function provided by Debug.Trace from the standard library is a
good way to inspect the values of variables from pure code while debugging. The
following function is nifty way to get a print out of particular values through
the computation.
import Debug.Trace (trace, traceShow) -- | Helper function while debugging. -- -- >>> showAndTell "foo: " 1 -- foo: 1 -- 1 -- showAndTell :: Show a => String -> a -> a showAndTell msg x = trace (msg ++ show x) x
The GHC user guide has a section on the GHCI debugger.
.cabal and Cabal
The first part of a cabal file is called the package properties and then
definitions that come after that are called stanzas. You can use common
stanzas to keep cabal files DRY. There is also dhall-to-cabal if you want a
more powerful way to write cabal files.
stack and friends
stack and cabal are the main build tools for haskell. stack was created as a more user friendly version of cabal.
Installation, upgrading and uninstalling
There is a script from commercialhaskell which installs stack
curl -sSL https://get.haskellstack.org/ | sh
The executable is in /usr/local/bin by default. To upgrade stack there is
the stack upgrade command. To uninstall, remove the stack executable and
~/.stack and the .stack-work from any projects using stack.
stack installs to /home/<username>/.local/bin by default, so you should add
this to your path
export PATH=/home/<username>/.local/bin:$PATH
Help! .stack takes up too much space
The current solution to this appears to be just deleting .stack once in a
while. This is a little bit wasteful because you'll need to download a bunch of
dependencies afterwards the next time you build a project, but this does remove
what can otherwise be a huge directory of unneeded material.
Starting a new project
stack new <project-name> <template-name>
cd my-project
stack setup
stack build
stack exec my-project-exe
Here <project-name> is the name of the directory that will be created to house
the project and <template-name> is the template to use; I like the simple
template because it uses cabal directly and is free from clutter. If there is
only library code and no executables, then the simple-library might be a
cleaner choice. Packages get added to package.yaml under dependencies: and
you start the REPL with stack ghci. Projects are configured by the .cabal
file, for simple and simple-library. stack can use hpack to convert a
package.yaml file to a .cabal file.
Starting a new project (with white chocolate macadamia)
I wrote white-chocolate-macadamia which defines a minimalist project template.
It is hosted here. To start a new project with it use the following command
stack new my-project https://raw.githubusercontent.com/aezarebski/white-chocolate-macadamia/main/macadamia.hsfiles
Commands
If you are ever unsure about some aspect of stack, appending --help is
usually pretty enlightening. There are few ways to initialise a project using
some standard templates.
stack new <package-name> stack new <package-name> <template-name> # Use a particular template stack new <package-name> --bare <template-name> # Without subdirectory
To build the targets described in the .cabal file there is stack build, but
unless you need GHC to optimise the executable, adding the --fast flag will
make it run faster. There is also the --file-watch flag which will cause it to
recompile each time that files are edited. There are many commands within
stack which are listed in the documentation. Run the executable with
stack exec -- <target> [arguments]
To run the tests there is stack test. To build the documentation there is
stack haddock which if you only need the documentation of your dependencies,
you can speed up with --haddock-deps. Once you have the documentation build,
you can open the documentation for a particular package in the browser.
stack build --haddock-deps stack haddock --open <package>
To make the documentation searchable like the online version (though noticibly more responsive) you can run a hoogle server. But first you must index the documentation, and this will need to be done every time your dependencies change.
stack hoogle -- generate --local
stack hoogle -- server --local --port=8080
Building with nix
When using stack and nix, the haskell dependencies are managed by stack and only
the non-haskell dependencies are managed by nix. You need nix installed on your
system for this to work, it will not be installed by stack. Adding the following
to your stack.yaml file will tell stack that you want to build your package in
a nix shell with these packages available.
# stack.yaml nix: enable: true packages: [glpk, pcre]
You will need to double check that the resolver you have specified corresponds
to one of the GHC versions that are available in your nix channel. To find out
which versions of GHC are available to you, drop into a nix REPL with nix repl
and then load the available packages with :l <nixpkgs> then ask for a list of
the available compiler versions with lib.attrNames haskell.compiler.
Further notes
- use
cabal2nixto convert a project's cabal file into a nix derivation. As a result, every time the cabal file changes the nix derivation will need to be regenerated. - The
nix-buildcommand is used to build a package and thenix-shellcommand is used to enter a shell configured for development of the package. You'll one nix file for your overall package which imports the one that was generated bycabal2nix. - Despite being able to use nix to build your haskell project, Gabriel recommends sticking with cabal and just using nix to provision the development environment.
GHCUP
GHCUP is a tool to simplify the process of managing the Haskell toolchain. The following is a very nifty command to install a particular version of GHC and the associated language server for your IDE.
# set the currently "active" GHC version ghcup set ghc 8.4.4
Profiling programs with stack
Stack provides some features to help make use of GHC's profiling features. This
is useful if you are trying to find bottleneck's in your program. If you want to
benchmark different methods you probably want to look at criterion.
- Recompile your project with
--profile
stack build --profile
- Run the program passing the correct flags to the run time
stack --profile exec -- my-program +RTS -p
- Inspect the resulting
.proffile.
One way to inspect the .prof file is to use the profiteur tool to generate a
tree map of both the time and allocation required to run the program. This
program can be downloaded via nix.
nix-shell -p haskellPackages.profiteur profiteur my-program.prof firefox my-program.prof.html
Benchmarking with criterion
Criterion is the tools for benchmarking code. This is useful if you have a couple of candidate implementations of a computation and you want to compare them. If you want to find bottle nexts in you program, you probably want to look at stack's profiling features
You build an application with defaultMain which sets up the benchmarks with a
CLI. The defaultMain expects a [Benchmark], you group multiple benchmarks
with bgroup, you create Benchmark objects with bench.
If you want to use some pre-computed environment variables in a benchmark, you
need the env function to manage this. The following snippet demonstrates how
to do this, generating some random variables once, and then passing them into a
function.
module Main where import Control.Monad import Criterion.Main import qualified Data.Vector as V import Statistics.Sample import qualified System.Random.MWC as MWC sampleMeanBench :: String -> [Double] -> Benchmark sampleMeanBench name xs = bench name $ nf (mean . V.fromList) xs getRandomList :: Int -> IO [Double] getRandomList n = do gen <- MWC.create foo <- replicateM n (MWC.uniform gen) return foo -- Our benchmark harness. main = defaultMain [ bgroup "meanPure" [ sampleMeanBench "small" [1 .. 10] , sampleMeanBench "medium" [1 .. 100] , sampleMeanBench "large" [1 .. 1000] ] , bgroup "meanEnv" [ env (getRandomList 10) (\xs -> sampleMeanBench "small" xs) , env (getRandomList 100) (\xs -> sampleMeanBench "medium" xs) , env (getRandomList 1000) (\xs -> sampleMeanBench "large" xs) ] ]
This could be run with the following to get a HTML report as output.
$ stack exec -- criterion-demo --output report.html
Note that in the linear regression results reported, this considers the relationship between the number of evaluations and the time that required.
Documentation with haddock
Markup
/italics/__bold__'hyperlink'@monospace@[some link](http://example.com)
Haddock supports LaTeX syntax for rendering mathematical notation. The delimiters are \[...\] for displayed mathematics and \(...\) for in-line mathematics.
-- | This is an enumerated list: -- -- (1) first item -- 2. second item -- -- This is a bulleted list: -- -- * first item -- * second item
Functions
-- | Two examples are given below: -- -- >>> fib 10 -- 55 -- -- >>> putStrLn "foo\nbar" -- foo -- bar f :: Int -- ^ The 'Int' argument -> Float -- ^ The 'Float' argument -> IO () -- ^ The return value
Data
data T a b -- | This is the documentation for the 'C1' constructor = C1 a b -- | This is the documentation for the 'C2' constructor | C2 a b
Records
Sometimes hindent will reformat record definitions in a way that does not
appear to be compatible with haddock.
data R a b = C { -- | This is the documentation for the 'a' field a :: a, -- | This is the documentation for the 'b' field b :: b }
Usage
Build and open the documentation in the browser. This does not seem to work well
from eshell but works fine from a bash shell.
stack haddock stack haddock --open
But a much quicker way to is to not build the documentation for the dependencies by using the following command instead.
stack haddock --no-haddock-deps --open
Linting hindent
hindent is a pretty printer which can be used to lint Haskell code.
Install it with stack install hindent and pay attention to where it installs because you need that on your path.
There is an Emacs minor mode, hindent-mode, which exposes the functionality of this program: hindent-reformat-*.
I have the following shortcuts:
SPC o h h rowner haskell hindent regionSPC o h h bowner haskell hindent buffer
Haskell layer in Spacemacs
To enable the Haskell layer add the following to dotspacemacs-configuration-layers.
(haskell :variables haskell-enable-hindent-style "johan-tibell" haskell-process-type 'stack-ghci)
If you want to make use of hindent, you'll need to make sure that the
executable is on the path Emacs uses: exec-path or eshell-path-env.
Programming
CLI
The function getArgs from System.Environment in base is how you get
command line arguments.
import System.Environment main = do a <- getArgs print a return ()
The following example demonstrates how you might get some data from a user at the command line at run time rather than data about how the program was called.
main :: IO () main = do putStrLn "Do you want to continue? [y/n]" response <- getChar if response == 'n' then do putStrLn "\nmaybe next time :)" return () else if response /= 'y' then do putStrLn "\n\nI doughnut understand..." main else do putStrLn "\nwoohoo!" return ()
Testing hspec
Add hspec to your dependencies and observe the following example
import Test.Hspec import Control.Exception (evaluate) main :: IO () main = hspec $ do describe "Prelude.head" $ do it "returns the first element of a list" $ do head [23 ..] `shouldBe` (23 :: Int) it "throws an exception if used with an empty list" $ do evaluate (head []) `shouldThrow` anyException
Testing hspec and QuickCheck
You can use QuickCheck in your Hspec tests
{-# LANGUAGE DeriveGeneric #-} module Main where import GHC.Generics import Generic.Random (genericArbitraryU) import Test.Hspec import Test.QuickCheck (Gen(..), forAll, property, choose) data RickMorty = Fleeb | Squanch | Plumbus deriving (Show, Generic, Eq) main :: IO () main = hspec $ do describe "read" $ do it "fooo" $ property $ foo it "baar" $ forAll (genericArbitraryU :: Gen RickMorty) bar it "baaz" $ forAll (choose (1, 3) :: Gen Int) foo foo :: Int -> Bool foo x = x == x bar :: RickMorty -> Bool bar x = x == x
The simplest way to use QuickCheck is via the property function which just
takes a predicate based on some standard types. If you want to provide your own
generator you need to use the forAll function, but once this has happened you
are free to use a wider range of generators. In the example above we just sample
uniformly from our RickMorty type. This is further demonstrated by the example
with choose which will generate integers from \(1\) to \(3\) inclusive as test
cases.
Handy IO
Writing a list of values to CSV
The following assumes that the type Foo is an instance of Csv.ToRecord which
can often be derived.
import qualified Data.ByteString.Lazy as L import qualified Data.Csv as Csv L.writeFile "output.csv" (Csv.encode (foos :: [Foo]))
Boring haskell and rio
The documentation for the rio package gives an opinionated view which features
of haskell are mature and useful enough to warant inclusion in production code.
The rio package itself is intended as a safe and sufficient Prelude
replacement. The authors suggest the following lists of language extensions and
compiler flags are fine to use if they are helpful.
Language extensions
AutoDeriveTypeable BangPatterns BinaryLiterals ConstraintKinds DataKinds DefaultSignatures DeriveDataTypeable DeriveFoldable DeriveFunctor DeriveGeneric DeriveTraversable DoAndIfThenElse EmptyDataDecls ExistentialQuantification FlexibleContexts FlexibleInstances FunctionalDependencies GADTs GeneralizedNewtypeDeriving InstanceSigs KindSignatures LambdaCase MonadFailDesugaring MultiParamTypeClasses MultiWayIf NamedFieldPuns NoImplicitPrelude OverloadedStrings PartialTypeSignatures PatternGuards PolyKinds RankNTypes RecordWildCards ScopedTypeVariables StandaloneDeriving TupleSections TypeFamilies TypeSynonymInstances ViewPatterns
Note that Alexis King thinks that PatternSynonyms are safe to enable by
default.
Compiler flags
-Wall -Wcompat -Widentities -Wincomplete-record-updates -Wincomplete-uni-patterns -Wpartial-fields -Wredundant-constraints
and -Werror for production.
Syntax
Naming conventions
Kowainik has an excellent summary of naming conventions in Haskell.
| Pattern | Meaning |
|---|---|
go |
recursive helper function |
p |
predicate function argument |
xxx' |
strict version of xxx |
xxxF |
returns in a functor |
xxxA |
returns in a applicative |
xxxM |
returns in a monad |
xxxP |
returns a parser |
xxx_ |
discards result |
xxxL or xxxR |
traverse left/right |
xxxBy or xxxOn |
works with summary value |
unXxx, getXxx and runXxx |
extract data |
eliminator eg maybe |
remove constructor |
mkXxx |
apply constructor |
genericXxx |
polymorphic version |
isXxx |
predicate |
Function syntax
-- |wild card f (_:xs) = xs -- |as-pattern f l@(x:xs) = x:l -- |guards f x | x < 0 = 0 | x >= 0 = 1 | otherwise = undefined -- |case expression f x = case x of pattern1 -> expression1 pattern2 -> expression2 _ -> undefined -- |where clause f x = g z where z = epxression -- |let expression f x = let z = expression in g z
If you have the MultiWayIf extension you can use guard style syntax in a
conditional as demonstrated in the following example from the School of Haskell:
{-# LANGUAGE MultiWayIf #-} fn :: Int -> Int -> String fn x y = if | x == 1 -> "a" | y < 2 -> "b" | otherwise -> "c" -- | should print: -- @c@ main = putStrLn $ fn 3 4
Records syntax
There is "Record Update Syntax" to construct a new record with some of the fields taking different values.
data Foo = Foo {a :: Int, b :: Char} deriving (Show) foo1 = Foo 1 'a' -- Foo {a = 1, b = 'a'} foo2 = foo1 {b = 'b'} -- Foo {a = 1, b = 'b'}
The RecordWildcards extension provides some additional sugar for pattern
working with records. It makes the fields available in the local scope under the
name of their accessors. The same is true for record construction. For example
{-# LANGUAGE RecordWildCards #-} data Person = Person { name :: String , admin :: Bool } example :: Person example = Person{..} where name = "John Doe" admin = True
The NamedFieldPuns extensions attempts to make it easier to construct and
reference values in a record. With this extension enabled, this
data C = C {a :: Int} f (C {a = a}) = a
can be written as this
f (C {a}) = a
It is possible to mix the effects of RecordWildCards and NamedFieldPuns, eg
C {a = 1, b, ..}.
Types syntax
data Person = Person { personFirstName :: String , personLastName :: String , personAge :: Int } deriving (Show, Eq)
It is considered decent to prefix the attributes with something that is unique to the record type to avoid name clashes.
If you have a wrapper type and want to access the data within but do not want to
continually pattern match to get the value out you can use the coerce function
from Data.Coerce (which is part of base). This functionality is encoded in the
Coercible typeclass.
List comprehensions
List comprehensions are a nice way to combine a map and a filter.
[sqrt x | x <- [1..9], x > 3]
You can use pattern matching to filter in a list comprehension as the following example demonstrates
data Foobar = Foo Int | Bar Char deriving (Show) x = [Foo 1, Bar 'a', Foo 2, Bar 'b'] y = [n | (Foo n) <- x]
The variable y has the value [1,2].
Variable names
Underscore, "_", is treated as a lower-case letter, and can occur wherever a lower-case letter can. However, "_" all by itself is a reserved identifier, used as wild card in patterns. Compilers that offer warnings for unused identifiers are encouraged to suppress such warnings for identifiers beginning with underscore. This allows programmers to use "_foo" for a parameter that they expect to be unused.
Module names
Module names are alphanumeric and must begin with an uppercase letter.
Typeclasses
class Eq a where (==) :: a -> a -> Bool (/=) :: a -> a -> Bool x == y = not (x /= y) x /= y = not (x == y) data Foobar = Foo | Bar instance Eq Foobar where Foo == Foo = True Bar == Bar = True _ == _ = False
There are cases where a class will have multiple type parameters, e.g. a, b,
and c, but one of them may be determined by the others, c is determined by
a and b. One way to resolve this is by adding type annotations, but this is
unpleasant. Functional dependencies are a way to tell the compiler that c is
determined by a and b. The following snippet gives an example of the syntax
(a vertical bar, |) used to acheive this
class Foo a b c | a b -> c where ...
let and where
As stated on the Haskell wiki page "Let vs. Where"
It is important to know that
let ... in ...is an expression, that is, it can be written wherever expressions are allowed. In contrast,whereis bound to a surrounding syntactic construct, like the pattern matching line of a function definition.
Monad transformers with mtl
ReaderT
To avoid explicitly passing environment data around, one can use the ReaderT
monad transformer to add read-only environment. The following example shows the
reader monad transformer in action.
import Control.Monad.Reader (ReaderT, ask, liftIO, runReaderT) data Env = Env { envInput :: FilePath } step1 :: ReaderT Env IO Int step1 = do liftIO $ putStrLn "Greetings from Step 1." return 0 step2 :: Int -> ReaderT Env IO () step2 n = do liftIO $ putStrLn (show n) fp <- envInput <$> ask line <- liftIO $ readFile fp liftIO $ putStr ("Autobots, " ++ line) main :: IO () main = do runReaderT (step1 >>= step2) (Env "autobots.txt")
The main function sets up an environment which is passes to Step 1 which puts
a value of 0 in the monad. Then in the second function the value is printed and
the contents of the file referenced in the environment is printed out, i.e., the
file autobots.txt which just contains a single line with "roll out". Running
this in the REPL gives the following output.
λ> main Greetings from Step 1. 0 Autobots, roll out
ReaderT on ExceptT
The example above using the reader monad transformer can be extended to improve the error handling in the case where the file path in the environment does not exist.
import Control.Monad.Except (ExceptT, runExceptT, throwError) import Control.Monad.Reader (ReaderT, asks, liftIO, runReaderT) import System.Directory (doesFileExist) newtype Env = Env { envInput :: FilePath } type Robot a = ReaderT Env (ExceptT String IO) a runRobot :: Robot a -> Env -> IO (Either String a) runRobot robot env = runExceptT (runReaderT robot env) step1 :: Robot Int step1 = do liftIO $ putStrLn "Greetings from Step 1." return 0 step2 :: Int -> Robot () step2 n = do liftIO $ print n fp <- asks envInput exists <- liftIO $ doesFileExist fp if exists then do line <- liftIO $ readFile fp liftIO $ putStr ("Autobots, " ++ line) else throwError "Could not find file in step 2"
The main function has been remove but there is not much added code here.
Running the runRobot function in the REPL we get the following results which
demonstrate how the failure path evaluates.
λ> runRobot (step1 >>= step2) (Env "autobots.txt") Greetings from Step 1. 0 Autobots, roll out Right () λ> runRobot (step1 >>= step2) (Env "autobats.txt") Greetings from Step 1. 0 Left "Could not find file in step 2"
Data structures and types
Int and Word
The package Data.Int provides signed integers and Data.Word provides
unsigned integers. The latter may be useful to encode that the number has to be
positive at the type level.
Strings
Strings are just lists of characters which can lead to poor preformance, which
is why people warn that String should be avoided if you are doing anything
serious with text. Still, for the cases where performance isn't going to be a
problem strings are simple to work with. The printf function in base
provides string interpolation.
import Text.Printf (printf) a = printf "foo %d" 1 :: IO () b = printf "bar %d" 2 :: String
The variable a stores and action which prints "foo 1" and b is a string:
"bar 2".
Semigroup
A semigroup is a set with an associative binary operation. In base this type
class, Data.Semigroup, requires a function <>, and instances of this function must be
associative.
Monoid
A monoid is a semigroup which has an identity element. In base this type
class, Data.Monoid, requires the function <>, as in semigroup, and mempty
for the identity element. The mempty must be both a left and right identity.
Data.List.NonEmpty(inbase) for non-empty lists to avoid run time errors due to bad calls toheadortail.containershas several efficient data structures that can be used as an alternative to lists.Data.Mapfor look-up tablesData.Sequenceif you finite lists you can access from both endsData.Setfor sets of elements inEqandOrd
vectorhas vectors.
Foldable
A data structure that reduced to a single summary value: foldr :: (a -> b -> b)
-> b -> t a -> b. For example, you might add up all the values on a tree where
each node has a value. When the data form a monoid foldMap can be implemented
instead which just uses the monoid's addition.
Traversable
Like a more powerful functor: traverse :: Applicative f => (a -> f b) -> t a ->
f (t b)
ST monad
Example
import Control.Monad (replicateM_,liftM) import Control.Monad.ST (runST) import Data.STRef foo :: String foo = runST $ do ref <- newSTRef "hello " x <- readSTRef ref writeSTRef ref (x ++ "world") readSTRef ref
Another example
Next time you have tricky fold, the following might be useful. Note that we use
the modifySTRef' with the apostrophe, which is the strick version of the
function to avoid the build up of thunks which might otherwise be a problem.
import Control.Monad (replicateM_,liftM) import Control.Monad.ST (runST) import Data.STRef fib :: Int -> Int fib n = runST $ do ref <- newSTRef (0,1) replicateM_ n $ modifySTRef' ref (\(a,b) -> (b,a+b)) liftM snd $ readSTRef ref
Moreover, this appears to be faster than the following non-tail recursive implementation
fib2 :: Int -> Int fib2 n | n < 2 = 1 | otherwise = fib (n-1) + fib (n-2)
Another example again
import Control.Monad.ST import Data.STRef import Data.Foldable sumST :: Num a => [a] -> a sumST xs = runST $ do n <- newSTRef 0 for_ xs $ \x -> modifySTRef n (+x) readSTRef n
Either monad
Definition
Missing MonadFail instance
Described here
instance MonadFail (Either String) where fail = Left
This sort of thing was ultimately rejected to preserve a neutral interpretation of how the Either monad would should work.
JSON with Aeson
For additional notes on JSON see my json notes.
aeson is the package for working with JSON. The important functions provided
are encode and decode and the typeclasses ToJson and FromJson which
ensure a type can be encoded and decoded. They can be derived automatically
along with Generic, although this requires the DeriveGeneric extension to be
include. The OverloadedStrings is also very useful to include. In addition to
loading import Data.Aeson as JSON you need to import GHC.Generics. This
stuff tends to work with lazy bytestrings, so there may be a little bit of
messing around to get that working but it is not too bad. The following are very
useful signatures to keep handy.
{-# LANGUAGE DeriveGeneric #-} import Data.Aeson decode :: FromJSON a => ByteString -> Maybe a encode :: ToJSON a => a -> ByteString encodeFile :: ToJSON a => FilePath -> a -> IO ()
Alternatively, you can use the ByteString type from the bytestring package
to write things to disk.
import Data.ByteString.Lazy writeFile :: FilePath -> ByteString -> IO () readFile :: FilePath -> IO ByteString
Note that when decoding an object from a JSON file, the order of the key-value pairs in the JSON does not matter, nor does the existance of additional fields provided the important ones can be parsed correctly.
There is a useful cheatsheet on parsing JSON from William Yao which may be worth looking at.
Pretty printing JSON
There is the aeson-pretty package to pretty print JSON values. The following
function might be useful as a quick toggle between the methods.
import qualified Data.Aeson as Json import qualified Data.Aeson.Encode.Pretty as Pretty -- | Write the object to file as JSON with optional pretty printing. encode2File :: Json.ToJSON a => Bool -> FilePath -> a -> IO () encode2File isPretty fp = L.writeFile fp . (if isPretty then Pretty.encodePretty else Json.encode)
GHC extensions
OverloadedStrings
Allows you to use string literals to mean other string-ey type things.
For instance, this would be useful when working with Text.
UnicodeSyntax
This allows you to make use of Unicode characters in your code which is particularly nice if you are going a verbatim translation of some mathematics. Emacs provides a nice way to make it easy to input Unicode.
Although this does not appear in the Boring Haskell recommendations, I suspect it has sufficient utility in scientific programming to warrant an exception.
OverloadedLists
This desugars list syntax to make it easier to use list syntax to construct things.
{-# LANGUAGE OverloadedLists #-} foo = [(1,2),(2,3)] :: Map Int Int
This will only work with the OverloadedLists extension.
View Patterns
The following example from Kowainik demonstrates nicely
mkUser :: Text -> Text -> User mkUser (Text.toLower -> nickname) (Text.toLower -> name) = User { userNickname = nickname , userName = name }
GHC extensions: DeriveX
DeriveFunctorDeriveFoldableDeriveTraversableGeneralizedNewtypeDerivingto make better use ofnewtype.
Packages I like
ad: combinators for automatic differentiation
aeson: a JSON parsing and encoding library
cassava: parsing and encoding RFC 4180 compliant CSV data
One example of using cassava is to make the Chain type from mcmc-types an
instance of ToRecord which makes it easier to write MCMC samples to a CSV. The
following snippet demonstrates how you might do this with an orphan-instance.
import Data.Csv import Data.Maybe (fromMaybe) import qualified Data.Vector as V instance (ToRecord a, ToRecord b) => ToRecord (Chain a b) where toRecord Chain {..} = V.concat [ (record [toField chainScore]) , (toRecord chainPosition) , fromMaybe V.empty (toRecord <$> chainTunables) ]
math-functions: various utilities for numerical computing
moo: provides building blocks to build genetic algorithms
monad-par which makes use of combinators in monad-par-extras
Without knowing anything about how this works internally, the following functions should be sufficient for running a map type computation in parallel.
import Control.Monad.Par (runPar) import Control.Monad.Par.Combinator (parMap) data Par a runPar :: Par a -> a parMap :: Traversable t => (a -> b) -> t a -> p (t b)
statistics: common functions and types useful in statistics
Scary and terrifying functions!!!
Scary
Data.List.sumandData.List.productusefoldlinstead offoldl'so can have poor performance.- Lots of the functions in
Data.Listare partial:head,init,last,tailand(!!)for example.
Terrifying
fromJust, always use ~fromMaybe- a -> Maybe a -> a~ instead.
Parallel execution
There is GHC.Conc.numCapabilities to see how many cores are available to the
runtime.
Evaluation with seq
There is a section on seq in Chapter 4 of Real World Haskell. In particular,
the following snippet from that chapter provides insight.
-- file: ch04/Fold.hs -- incorrect: seq is hidden by the application of someFunc -- since someFunc will be evaluated first, seq may occur too late hiddenInside x y = someFunc (x `seq` y) -- incorrect: a variation of the above mistake hiddenByLet x y z = let a = x `seq` someFunc y in anotherFunc a z -- correct: seq will be evaluated first, forcing evaluation of x onTheOutside x y = x `seq` someFunc y
Keep in mind that seq only evaluates up to the first constructor, and that
there is an additional cost with forcing evaulation since the runtime needs to
do a look up to determine if it has already been evaluated. Depending on what is
being evaluated this can even introduce a space leak.
Example
The very simple example given here demonstrates how to run code in parallel
using only the parallel library (which is maintained by
libraries@haskell.org so can be relied upon).
executable party
hs-source-dirs: src
main-is: Main.hs
default-language: Haskell2010
ghc-options: -threaded -O2
build-depends:
base >=4.7 && <5
, mwc-random
, parallel
, primitive >=0.7.1.0
, vector >=0.12.1.2
And the following Main.hs
module Main where import Control.Monad.Primitive (PrimMonad, PrimState) import Control.Monad.ST (runST) import Data.Vector.Unboxed (singleton) import Data.Word (Word32) import System.Random.MWC (asGenST, initialize) import Control.Parallel.Strategies import System.Environment (getArgs) main :: IO () main = do putStrLn "Hello" (inParallel:maxN:[]) <- getArgs let maxNInteger = read maxN :: Int ns = replicate maxNInteger 30 print $ "running up to " ++ maxN if inParallel == "true" then let results = (fib <$> ns `using` parListChunk 4 rdeepseq) :: [Integer] in do print "running parallel"; print $ sum results else let results = (fib <$> ns) :: [Integer] in do print "running serial"; print $ sum results putStrLn "Goodbye" fib :: Integer -> Integer fib n | n < 2 = 1 | otherwise = fib (n -1) + fib(n-2)
The following script is used to test out the performance of this code.
time stack exec party false 100 --rts-options -N1 time stack exec party false 100 --rts-options -N2 time stack exec party false 100 --rts-options -N4 time stack exec party true 100 --rts-options -N1 time stack exec party true 100 --rts-options -N2 time stack exec party true 100 --rts-options -N4
the results of this confirm that increasing the number of processors allowed to be used reduces the run time but there is a limit to how useful this will be.
| Number of threads | Serial | Parallel |
|---|---|---|
| 1 | 4.33 | 4.32 |
| 2 | 4.32 | 2.36 |
| 4 | 4.41 | 2.23 |
Hackage
Development shell
- There is a nix-shell to assist in testing your package in a reproducible environment described in my nix note. This provides a couple of utilities for building your package.
Notes about uploading a package to hackage
- Once a package is uploaded, it is there forever so make sure it is correct, that is why there is the package candidate system.
- The utility
cabal gen-boundsmakes it easy to generate suitable bounds on dependency versions. To keep the version bounds DRY you only need to specify them on their first occurrence in the cabal file. This will only work with an up to date version of cabal. - There is the
cabal-fmtpackage which you can use to format your cabal file, egcabal-fmt --inplace demo.cabal. - There is a cabal
sdistutility to zip up a package prior to submission. - When a package is updated the package versioning policy should be used to
update the package version. There is a useful decision tree to help you apply
this policy. A version must be of the form
A.B.Cwith an optional suffix of.D. - The command
stack sdistwill check the package for common mistakes and produce a tarball ready for uploading. When a package is uploaded, it may take a while for the documentation to be build and uploaded. - To use the uploaded package before it has made it onto stackage you can copy
the link for the tarball into
extra-depsin the stack YAML file. - Don't forget to
stack haddock --no-haddock-depsfirst to make sure that the documentation will build. Also, don't be surprised if the documentation does not appear online immediately, this can take a while. - There is a link to upload packages on the hackage page, you can use
stack upload .. Either way, you will need your hackage username and password.
Extracting example code
If you have examples in a source file using the >>> notation you can extract
it with the following one liner.
$ cat <path/to/hs> | grep "^-- >>>"
Type theory and functional programming
Haskell for science
I have some notes on numerics that might be useful.
Optimisation
Use moo for a rough estimate.
Root finding
Use statistics for finding roots if you know a bounding interval, with or
without derivatives, both Ridders and Newton have good convergence.
Differential equations
Consider
\[ \frac{dx}{dt} = \alpha x(t), \quad x(0) = x_0 \]
This example needs hmatrix and hmatrix-gsl.
import Numeric.GSL.ODE import Numeric.LinearAlgebra import Numeric.LinearAlgebra.Data alpha = 0.1 xdash _ [x] = [x * alpha] x0 = 1.0 ts = linspace 100 (0,3) numericSol = odeSolve xdash [x0] ts exactSol = asColumn $ x0' * exp (alpha' * ts) where x0' = scalar x0 alpha' = scalar alpha main :: IO () main = if maxElement (numericSol - exactSol) < 1e-10 then putStrLn "They are equal!" else putStrLn "Huge error :("
Random number simulation
import System.Random.MWC foobar :: IO (Double,Double) foobar = do gen <- create x1 <- uniform gen x2 <- uniform gen return (x1,x2)
This returns a pair of different numbers because it is working in an instance
of PrimMonad and managing the state between uses of gen. Multiple calls to
this function always return the same values because the create function starts
with a hardcoded seed in the library.
Numbers
To learn about how Haskell handles numbers — although we only really care
about Integer and Double — there is the report and a gentle introduction
available. The numeric-limits package provides some helpful functions for
working with this too.
Types
Naturalfor the natural numbersWordis unsigned integers of with a finite rangeIntegerfor arbitrary integers- not to be confused with the
Integraltypeclass
- not to be confused with the
Intfor a finite range of integersFloatfor single precision floating point numbers- You should opt for
Doublewhenever possible
- You should opt for
Doublefor double precision floating point numbers
Also the table here provides a description of how to map between the different numeric types.
Typeclasses
This graph shows the hierarchy of numeric typeclasses
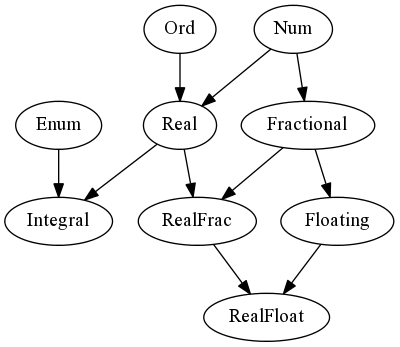
The most important one here is the Num typeclass which ensures you have basic
arithmetic. Ord is also important but is a bit more general.
Special functions
The math-functions package provides the Numeric.SpecFunctions module which
provides lots of useful functions: choose and logChoose for working with
binomial coefficients.
Visualisation
There are bindings to gnuplot provided by the gnuplot package. The documentation is a little bit patchy, but there is a decent list of examples. The easiest way is to copy the demo script and to modify the code in it to generate the plot you want. With this package you can render plots in a new window or write the results to file.
Example
module Main where import Data.Function ((&)) import GHC.IO.Exception (ExitCode) import qualified Graphics.Gnuplot.Advanced as GP import qualified Graphics.Gnuplot.Frame as Frame import qualified Graphics.Gnuplot.Frame.OptionSet as Opts import qualified Graphics.Gnuplot.Graph.TwoDimensional as Graph2D import Graphics.Gnuplot.Plot.TwoDimensional (linearScale) import qualified Graphics.Gnuplot.Plot.TwoDimensional as Plot2D import qualified Graphics.Gnuplot.Terminal.PNG as PNG main :: IO () main = do demo Nothing return () demo :: Maybe FilePath -> IO ExitCode demo maybeFilePath = case maybeFilePath of Just fp -> GP.plot (PNG.cons fp) foo Nothing -> GP.plotDefault foo where foo :: Frame.T (Graph2D.T Double Double) foo = Frame.cons plotOptions $ layer1 <> layer2 plotOptions = Opts.deflt & Opts.title "hello" & Opts.key False layer1 = Plot2D.function Graph2D.lines (linearScale 200 (-10,10)) (\x -> x * cos x / (1 + x^ 2) ) layer2Data = zip [-10..] (take 21 (concat (repeat [-1,0,1]))) layer2 = Plot2D.list Graph2D.points $ layer2Data
Mutable arrays
Sometimes it is much more efficient to use a mutable array. Here is an example of how to do this in the ST monad.
import Control.Monad (forM_) import Data.Array.MArray (newArray, writeArray) import Data.Array.ST (runSTUArray) import Data.Array.Unboxed (assocs) import Data.STRef (newSTRef, readSTRef, writeSTRef) foo :: [(Char, Int)] foo = assocs $ runSTUArray $ do index <- newSTRef 'a' ar <- newArray ('a', 'z') 0 forM_ [1..26] $ \n -> do ix <- readSTRef index writeArray ar ix n writeSTRef index (succ ix) return ar
Note that in this example we have used an STUArray. There is also the
STArray which admits a wider range of types for the elements of the array,
however the STUArray is meant to have better performance. Don't forget to
check the provided instances of MArray to make sure that both your index and
element types have the necessary instances.