AANN 22/02/2024
Early stopping
In this example we consider an approach to early stopping described by Lutz Prechelt (1998). They propose several classes of stopping criteria. We will consider the third class because it is the simplest and there doesn't seem to be a clear winner among the different classes. The idea of the stopping criteria is to stop the training loop once there have been \(s\) consecutive instances when the validation error has increased. The hyperparameter \(s\) is then used to tune how early we stop.
As an example, we will consider the same CNN network used for MNIST classification in this previous post and provide an example of a helper validation manager class that implements the early stopping rule. This ends up taking a bit longer to run, but it gives us a reasonable justification for stopping the training, beyond saying "we ran out of time to keep training". This gives us a model that gets an accuracy of \(99\%\) on the validation set, but it takes a \(<5\) minutes to train.
Loading packages
There are two packages we will use that haven't seen much action in
previous posts: collections which provides a deque, and copy which
is useful to copying model states. You could easily get away without
using these, but they make some of the code a little cleaner and they
are both part of the standard library.
import collections import copy import time import torch import torch.nn as nn import torch.optim as optim torch.manual_seed(0) import numpy as np import pandas as pd import plotnine as p9 from plotnine import * import sys import os from pathlib import Path current_directory = Path(os.getcwd()) sys.path.append(str(current_directory)) import niceneuron.plot as nn_plot import niceneuron.io as nn_io import niceneuron.data as nn_data
Setting data and filenames
As usual there is a bit of fuss here to get the data all set up. This can be skipped on a first reading.
images_path = "data/train-images.idx3-ubyte" labels_path = "data/train-labels.idx1-ubyte" test_images_path = "data/t10k-images.idx3-ubyte" test_labels_path = "data/t10k-labels.idx1-ubyte" loss_csv = "example-2024-02-22/loss.csv" training_png = "example-2024-02-22/training.png" images = nn_io.read_idx(images_path) images = images.astype(np.float32) labels = nn_io.read_idx(labels_path) train_dataset = nn_data.MNISTDataset(images, labels, flatten=False, normalise=True) train_dataloader = torch.utils.data.DataLoader( train_dataset, batch_size=64, shuffle=True ) test_images = nn_io.read_idx(test_images_path) test_images = test_images.astype(np.float32) test_labels = nn_io.read_idx(test_labels_path) test_dataset = nn_data.MNISTDataset( test_images, test_labels, flatten=False, normalise=True ) test_dataloader = torch.utils.data.DataLoader( test_dataset, batch_size=64, shuffle=False )
Defining the network
This is the simple convolutional neural network we have used before.
class DemoCNN(nn.Module): def __init__(self): super(DemoCNN, self).__init__() self._conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2) self._pool1 = nn.AvgPool2d(2) self._conv2 = nn.Conv2d(6, 16, kernel_size=5, padding=0) self._pool2 = nn.AvgPool2d(2) self._fc1 = nn.Linear(5 * 5 * 16, 84) self._fc2 = nn.Linear(84, 10) self._relu = nn.ReLU() def forward(self, x): x = self._pool1(self._relu(self._conv1(x))) x = self._pool2(self._relu(self._conv2(x))) x = x.view(-1, 5 * 5 * 16) x = self._relu(self._fc1(x)) x = self._fc2(x) return x
Early stopping
The idea behind this method of early stopping is simple, keep training
until there are \(s\) consecutive increasing validation errors. To
simplify this, I have written a class ValidationManager which takes
care of this.
ValidationManager
This could more general, but it serves as a nice starting point for
creating these helper objects. The main methods to note are
validate, which runs the validation loop and records how the
training is going, and the should_stop_early predicate which checks
if the stopping criteria has been reached.
class ValidationManager: """ A class for managing early stopping during training. """ def __init__(self, model, loss_fn, patience=3): self._model = model self._loss_fn = loss_fn self._patience = patience self._loss_history = collections.deque([float("inf")] * patience) self._best_loss = float("inf") self._best_model = None self._validation_history = [] def validate(self, epoch, dataloader): cum_loss = 0 with torch.no_grad(): for images, label in dataloader: images = images.unsqueeze(1) logits = self._model(images) loss = self._loss_fn(logits, label) cum_loss += loss.item() if cum_loss < self._best_loss: self._best_loss = cum_loss self._best_model = copy.deepcopy(self._model.state_dict()) self._validation_history.append((epoch, cum_loss)) self._loss_history.popleft() self._loss_history.append(cum_loss) def should_stop_early(self): return all( self._loss_history[i] < self._loss_history[i + 1] for i in range(self._patience - 1) ) def get_validation_history(self): return self._validation_history def get_best_model(self): return self._best_model
Training loop (with early stopping)
Here we have the same training loop as used in the past, but now slightly cleaner thanks to the validation manager object.
model = DemoCNN() loss_fn = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=1e-3) validation_manager = ValidationManager(model, loss_fn, patience=4) model.train() loss_history = [] training_start_time = time.time() for epoch in range(30): epoch_cumloss = 0 for images, label in train_dataloader: images = images.unsqueeze(1) logits = model(images) loss = loss_fn(logits, label) epoch_cumloss += loss.item() optimizer.zero_grad() loss.backward() optimizer.step() print(f"Epoch {epoch} loss: {epoch_cumloss}") loss_history.append((epoch, epoch_cumloss)) validation_manager.validate(epoch, test_dataloader) if validation_manager.should_stop_early(): break training_finish_time = time.time() print(f"Training took: {training_finish_time - training_start_time}")
Visualise the training
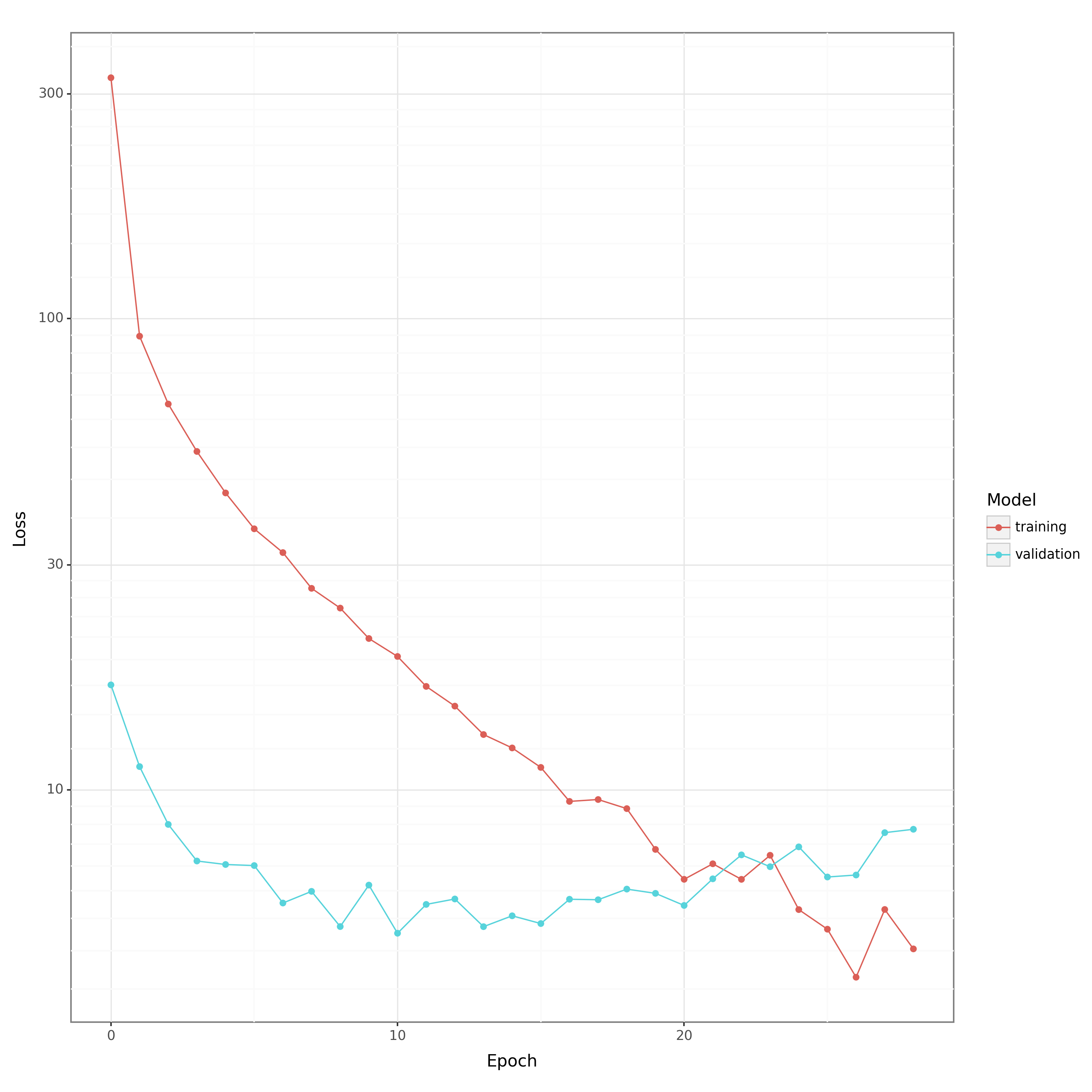
Figure 1: Testing and validation errors during the training loop.
loss_df = pd.DataFrame(loss_history, columns=["epoch", "loss"]) loss_df["model"] = "training" validation_df = pd.DataFrame( validation_manager.get_validation_history(), columns=["epoch", "loss"] ) validation_df["model"] = "validation" plot_df = pd.concat([loss_df, validation_df], axis=0) plot_df.to_csv(loss_csv, index=False) training_p9 = nn_plot.plot_loss_curve(plot_df) + p9.scale_y_log10() training_p9.save(training_png, width=10, height=10, dpi=300)
Testing the model
We end up with \(99\%\) accuracy, as expected 🥳
best_model = validation_manager.get_best_model() model.load_state_dict(best_model) model.eval() correct = 0 total = 0 with torch.no_grad(): for images, label in test_dataloader: images = images.unsqueeze(1) logits = model(images) predicted = torch.argmax(logits, dim=1) total += label.size(0) correct += (predicted == label).sum().item() print(f"Test accuracy: {correct / total}")
Discussion
Early stopping provides an uncontroversial stopping criteria. Empirical results from Lutz Prechelt (1998) suggests there isn't a universally best criteria and the one used here seems intuitive and simple so presents a nice choice.
The ValidationManager class — see here — may be over-doing it a
little, but it does keep a lot of the details out of the training loop
which is nice. The class could be made a bit more general, but this is
just a proof-of-concept of the value of a validation manager.